This is a rather short post on a little fun project I did a couple of weekends ago. The purpose was mostly to demonstrate how easy it is to process and visualize large amounts of data using Python and d3.js.
With the goal of visualizing the words that were most associated with a given scientist or philosopher, I downloaded a variety of science and philosophy books that are in the public domain (project Gutenberg, more specifically), and processed them using Python (scikit-learn and nltk), then used d3.js and d3.js cloud by Jason Davies (https://github.com/jasondavies/d3-cloud) to visualize the words most frequently used by the authors. To make it more interesting, only words that are somewhat unique to the author are displayed (i.e. if a word is used frequently by all authors then it is likely not that interesting and is dropped from the results). This can be easily achieved using the max_df parameter of the CountVectorizer class.
Let's look at some screen-shots first. Click on the link below to see the d3.js SVG version, though beware that it might take a minute or two to render on your computer. You can make it more fun by trying to guess who the scientist/philosopher is by looking at the words, prior to reading the caption!

Bertrand Russell Wordcloud - Click For Large SVG Version (Might take a few minutes to load.)
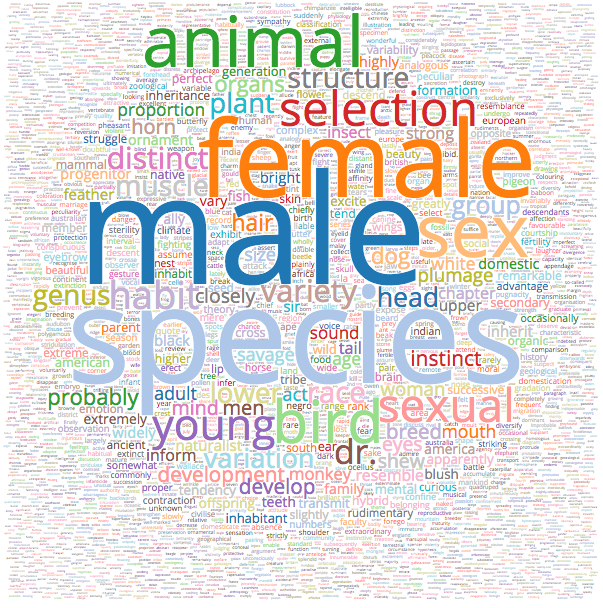
Charles Darwin Wordcloud - Click For Large SVG Version (Might take a few minutes to load.)
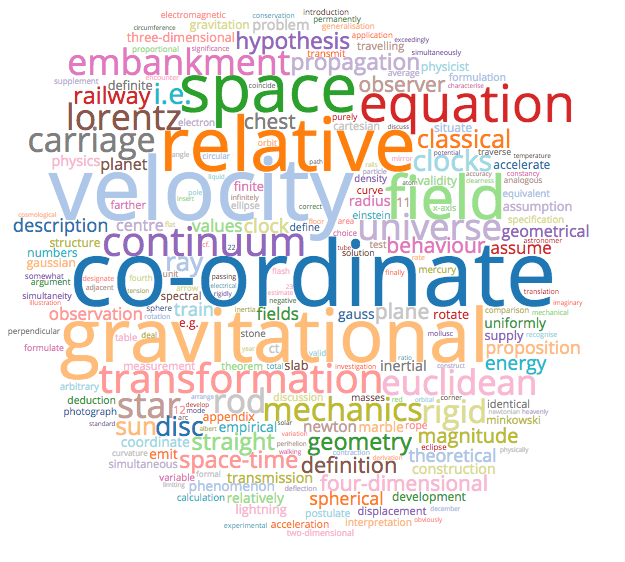
Henri Poincare Wordcloud - Click For Large SVG Version (Might take a few minutes to load.)
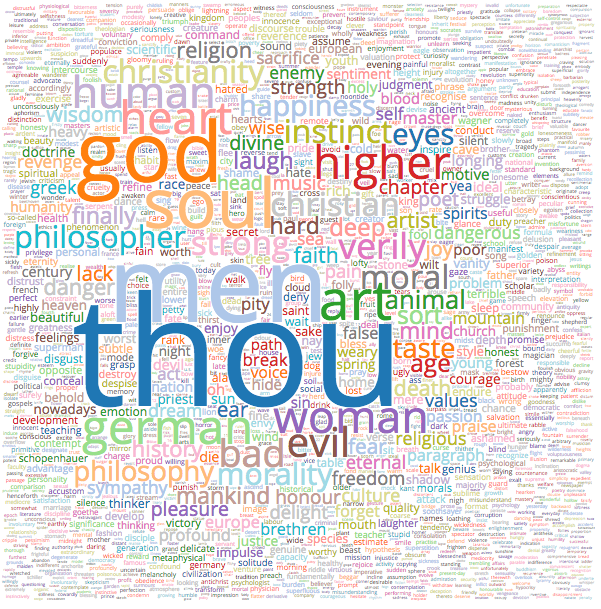
Friedrich Nietzsche Wordcloud - Click For Large SVG Version (Might take a few minutes to load.)
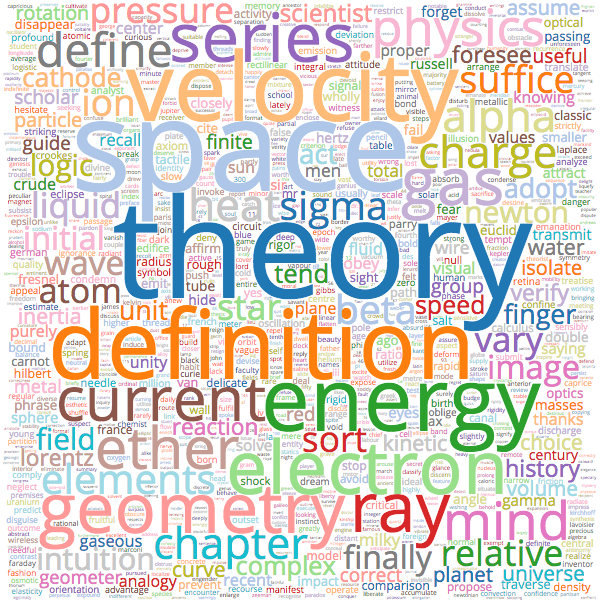
Albert Einstein Wordcloud - Click For Large SVG Version (Might take a few minutes to load.)
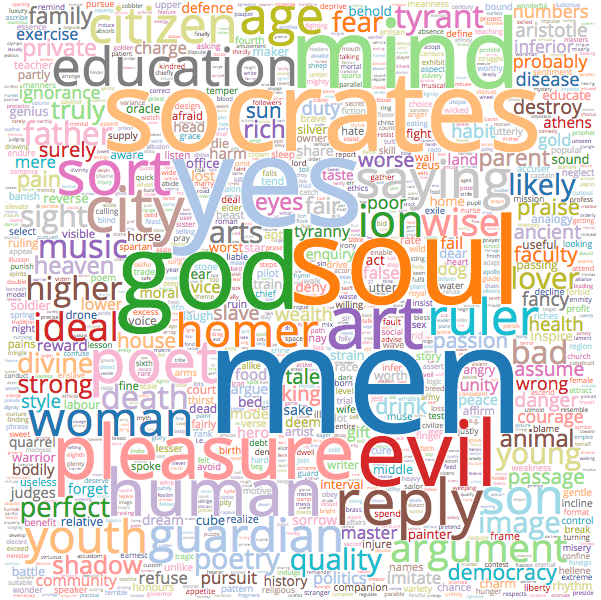
Plato Wordcloud - Click For Large SVG Version (Might take a few minutes to load.)
And here's the code, as promised. First, the Python script to extract the data. The script will expect the data to be in a ./data subdirectory, with the structure ./data/<philosopher>/<book>.txt. The book name does not matter, but the <philosopher> part is used as the name of the output HTML file. The output is written to an HTML file in ./output using a Jinja2 template. If you have any questions or suggestions, post a comment below.
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
from glob import glob
from nltk import word_tokenize
from nltk.corpus import wordnet as wn
from sklearn.feature_extraction.text import CountVectorizer
import codecs
import jinja2
import json
import os
def get_raw_data():
for dirname in glob('data/*'):
philosopher = os.path.split(dirname)[-1]
texts = []
for filename in glob(os.path.join('data', philosopher, '*.txt')):
with codecs.open(filename, 'r', 'utf-8') as file:
texts.append(file.read())
yield philosopher, '\n'.join(texts)
class StemTokenizer(object):
def __init__(self):
self.ignore_set = {'footnote', 'nietzsche', 'plato', 'mr.'}
def __call__(self, doc):
words = []
for word in word_tokenize(doc):
word = word.lower()
w = wn.morphy(word)
if w and len(w) > 1 and w not in self.ignore_set:
words.append(w)
return words
def process_text(counts, vectorizer, text, philosopher, index):
result = {w: counts[index][vectorizer.vocabulary_.get(w)]
for w in vectorizer.get_feature_names()}
result = {w: c for w, c in result.iteritems() if c > 4}
normalizing_factor = max(c for c in result.itervalues())
result = {w: c / normalizing_factor
for w, c in result.iteritems()}
return result
def main():
data = list(get_raw_data())
print('Data loaded')
n = len(data)
vectorizer = CountVectorizer(stop_words='english',
max_df=(n-1) / n,
tokenizer=StemTokenizer())
counts = vectorizer.fit_transform(text for p, text in data).toarray()
print('Vectorization done.')
for i, (philosopher, text) in enumerate(data):
result = process_text(counts, vectorizer, text, philosopher, i)
loader = jinja2.FileSystemLoader(searchpath='templates')
env = jinja2.environment.Environment(loader=loader)
words = json.dumps(result)
template = env.get_template('wordcloud.jinja2')
template_data = {'words': words,
'width': 1200,
'height': 1200,
'rescale': 250}
with codecs.open('output/{}.html'.format(philosopher),
'w', 'utf-8') as result_file:
result_file.write(template.render(template_data))
print('Processing done for {}'.format(philosopher))
if __name__ == '__main__':
main()
And the HTML Jinja2 template, with d3.js code:
<!doctype html>
<html lang="en">
<head>
</head>
<body>
<script src="//code.jquery.com/jquery-2.1.1.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/d3/3.4.8/d3.min.js"></script>
<script src="/js/libs/d3.layout.cloud.min.js"></script>
<div style="padding: 5px;" id="word-cloud"></div>
<script>
var words = {{ words|safe }};
function drawWordCloud(rescale)
{
width = {{ width }};
height = {{ height }};
fontFamily = "Open Sans";
var fill = d3.scale.category20();
d3.layout.cloud().size([width, height])
.words(Object.keys(words).map(function(d)
{
return {
text: d,
size: 7 + words[d] * rescale
};
}))
.padding(1)
.rotate(function()
{
// Uncomment and change this line if you want the words to
// be rotated. Returning 0 makes all the words horizontal.
// return ~~(Math.random() * 2) * 90;
return 0;
})
.font(fontFamily)
.fontSize(function(d)
{
return d.size;
})
.on("end", draw)
.start();
function draw(words)
{
d3.select("#word-cloud").append("svg")
.attr("width", width)
.attr("height", height)
.append("g")
.attr("transform", "translate(" + width / 2 + ", " + height / 2 + ")")
.selectAll("text")
.data(words)
.enter().append("text")
.style("font-size", function(d)
{
return d.size + "px";
})
.style("font-family", fontFamily)
.style("fill", function(d, i)
{
return fill(i);
})
.attr("text-anchor", "middle")
.attr("transform", function(d)
{
return "translate(" + [d.x, d.y] + ")rotate(" + d.rotate + ")";
})
.text(function(d)
{
return d.text;
});
}
}
drawWordCloud({{ rescale }});
</script>
</body>
</html>
Comments