1 Introduction
Why is it that, for me, combinatorics arouses feelings of pure pleasure, yet, for many others it evokes feelings of pure panic? - Don Knuth, The Art of Computer Programming, Vol. 4
The goal of combinatorial generation (or searching as Knuth calls it) is to exhaustively produce a set of combinatorial objects, one at a time, often subject to some constraints, and often in a certain required order. Both [KNUTH-4A] and [RUSKEY] provide excellent introductions to the subject of combinatorial generation. Combinatorial generation problems encompass a wide range of problems, from relatively simple (e.g. generating all subsets or all permutations) to rather complex (e.g. generating all ideals of a poset in Gray order).
Algorithms for combinatorial generation are often divided into iterative and recursive categories. Iterative algorithms have traditionally been considered superior in performance due to the overhead of repetitive function calls in recursive algorithms. Arguably, this advantage is less noticeable when recursion is used properly (no redundant subtrees in the recursion tree) and modern compilers are used. Recursive algorithms, on the other hand, often have the advantage of being easier to read and understand.
These two types of algorithms can be further considered as ways of approaching a combinatorial generation problem. That is, there are a few problem-solving strategies that work naturally with each type of algorithm. For example, with recursion, the main strategy involves reducing the problem to a subproblem. Similarly, with iterative algorithms the strategy of finding the next object in lexicographic order is quite commonly used and is rather powerful. Approaches that use the algebraic or arithmetic properties of the objects generated are also often used in iterative algorithms. We will see some examples of all of these in this article.
Coroutines, which can be seen as a generalization of functions, can encompass both recursive and iterative algorithms. As such, they provide an ideal mechanism for combinatorial generation. In fact, one of the most popular coroutine use patterns in modern programming languages is the generator pattern, which we will discuss in next section. As the name suggests, generators provide the perfect mechanism for implementing combinatorial generation algorithms, recursive or iterative.
In addition, since coroutines are a generalization of functions, we can exploit their generality to come up with combinatorial generation algorithms that are arguably somewhere between recursive and iterative. These algorithms introduce a new strategy for approaching combinatorial generation, which can be taken as a third approach, in addition to recursive and iterative approaches.
This article is intended to provide an introduction to combinatorial generation using coroutines. Most of the discussion in this article will be through examples. Performance is discussed in a few of the examples as well. The main ideas presented here are either directly taken from those in [KR], or inspired by them. Most of the article is written with an intermediate or advanced programmer with a modest level of familiarity with combinatorics and combinatorial generation as the audience in mind, though the last few examples involve combinatorial objects beyond the basics.
Examples are all in Python, and all the source code included here is available at https://github.com/sahands/coroutine-generation for any readers who wish to experiment with the code interactively. You can also see the Prezi slides for this project here.
- A Note on Python 2 v.s. Python 3
- All the code in this article is written to be compatible with Python 2.5 to 3.3. However, I make the general assumption that Python 3 is in use, and as such make no effort to write code that would be more efficient in Python 2. For example, I use range instead of xrange, since in Python 3 xrange is removed and range returns an iterator instead of a list. However, in favour of compatibility with Python 2, no Python 3 specific feature (e.g. yield from) is used.
2 Coroutines and Their Implementation in Python
2.1 Basic Definition
As mentioned in the introduction, coroutines are a generalization of functions. Assume A is a function that calls B. In terms of the flow of execution, this involves A pausing its execution and passing the flow to B. As such, A can then be seen to be in a "paused" state until B finishes and returns execution back to the caller, A in this case. Coroutines generalize functions by allowing for any coroutine to pause its execution and yield a result at any point, and for any other coroutine to pass the execution to any other paused coroutine to continue. To achieve this, coroutines need to remember their state so they can continue exactly where they left off when resumed. The coroutine's "state" here refers to the values of local variables, as well as where in the coroutine's code the execution was paused.
In other words, coroutines are functions that allow for multiple entry points, that can yield multiple times, and resume their execution when called again. On top of that, coroutines can transfer execution to any other coroutine instead of just the coroutine that called them. Functions, being special cases of coroutines, have a single entry point, can only yield once, and can only transfer execution back to the caller coroutine.
2.2 Python Generators
In Python, generators, which are basic coroutines with a few restrictions, were introduced in [PEP-255]. The syntax for defining coroutines in Python is very similar to that of functions, with the main different being that instead of return the keyword yield is used to pause the execution and return the execution to the caller. The syntax for using generators is rather different from functions though, and is in fact closer to how classes are treated in Python: calling a generator function returns a newly created "generator object", which is is an instance of the coroutine independent of other instances. To call the generator, the next built-in function is used, and the generator object is passed to next as the parameter. Here is a very simple example demonstrating how a very simple function as be implemented as a coroutine using a generator in Python:
def add_func(a, b):
return a + b
def add_coroutine(a, b):
yield a + b
# Usage:
x = add_func(1, 2)
print(x)
# Equivalent to:
adder = add_coroutine(1, 2)
x = next(adder)
print(x)
# Further calls such as the following to adder will result in a StopIteration
# being raised.
x = next(adder)
Of course, the above example is meant to contrast the syntactic differences of generators and functions. The particular use of a coroutine demonstrated above is of course completely unnecessary. Let us look at a somewhat more interesting example, taken, with minor modification, from [PEP-255]:
def fib():
a, b = 0, 1
while True:
yield b
a, b = b, a + b
# Usage:
f = fib() # Create a new "instance" of the generator coroutine
print(next(f)) # Prints 1
print(next(f)) # Prints 1
print(next(f)) # Prints 2
print(next(f)) # Prints 3
print(next(f)) # Prints 5
Here we have a generator that yields the numbers in the Fibonacci sequence ad infinitum. Each call to the generator slides the a and b variables ahead in the sequence, and then execution is paused and b is yielded.
2.3 Recursive Generators
Before continuing, let us look at a simple example of a recursive algorithm implemented using coroutines as well. In this example, we create a very minimalistic binary tree and then print its post-order traversal. Notice how generators can be recursive, and how they implement the iterator interface which allows them to be used inside for loops and generator expressions.
def postorder(tree):
if not tree:
return
for x in postorder(tree['left']):
yield x
for x in postorder(tree['right']):
yield x
yield tree['value']
# Usage:
tree = lambda: defaultdict(tree)
# Let's build a simple tree representing (1 + 3) * (4 - 2)
T = tree()
T['value'] = '*'
T['left']['value'] = '+'
T['left']['left']['value'] = '1'
T['left']['right']['value'] = '3'
T['right']['value'] = '-'
T['right']['left']['value'] = '4'
T['right']['right']['value'] = '2'
postfix = ' '.join(str(x) for x in postorder(T))
print(postfix) # Prints 1 3 + 4 2 - *
In Python 3, with [PEP-380], the above can be made even simpler by using the yield from statement:
def postorder(tree):
if not tree:
return
yield from postorder(tree['left'])
yield from postorder(tree['right'])
yield tree['value']
However, the shorter and nicer Python 3 syntax will not be used for the rest of the article to keep the code Python 2 compatible.
2.4 PEP 342 and the Enhanced yield Keyword
Python generators were further generalized to allow for more flexible coroutines in [PEP-342]. Prior to the enhancements in [PEP-342], Python's generators were coroutines that could not accept new parameters after the initial parameters were passed to the coroutine. With [PEP-342]'s send method, a coroutine's execution can resume with further data passed to it as well. This is implemented by allowing the yield keyword to be used not just as a statement but also as an expression, the evaluation of which results in the coroutine pausing until a value is passed to it via send, which will be the value that the yield expression evaluates to. In this article, we will only need to use the generator pattern, and will only use yield as a statement meaning the send method will not be used.
2.5 Clarification Regarding Terminology
It is important to mention that in some Python literature the word "coroutine" has come to mean specifically coroutines that use yield as an expression and hence require the use of send to operate. See [BEAZLEY] for example (which, by the way, is an excellent introduction to coroutines and their uses in IO operations, parsing, and more). I believe this is somewhat inaccurate, since coroutines are a general concept, and functions, generators with next or send or both, all fall under coroutines. (That is, on an abstract level, the set of coroutines contains the set of generators and functions, and more.)
In this article, I use the word "coroutine" in its generality, as defined in the first paragraph of this section, in accordance with how Knuth defines the word in [KNUTH-1]. I also will more or less use it interchangeably with the word "generator", since we will only use coroutines that are generators in this article.
I will refer the readers interested in the enhanced yield keyword and its use to [BEAZLEY].
2.6 A Final Note on Coroutines in Python
Before we move on, it is important to note that even with [PEP-342], Python's generators do not implement coroutines in full generality. To quote [PY-1]:
All of this makes generator functions quite similar to coroutines; they yield multiple times, they have more than one entry point and their execution can be suspended. The only difference is that a generator function cannot control where should the execution continue after it yields; the control is always transferred to the generator's caller.
So unlike the way Knuth defines and uses coroutines, Python's generators are not completely symmetric; an executing generator object is still coupled to the caller, which creates asymmetry. However, this limitation will not be an issue for our purposes here.
3 Motivating Example: Multi-Radix Numbers
We start our exploration of coroutine-based combinatorial generation with a simple example: multi-radix numbers. The goal here is to provide a short and simple example of the common approaches to solving combinatorial generation problems, and then introduce the coroutine-based approach so as to emphasize the differences and advantages of each approach. The first approach will be based on arithmetical properties of the objects we are generating, the second will be a recursive solution based on a reduction to a subproblem, third will be an iterative approach based on explicitly finding the next lexicographic item, and finally, the fourth approach will be the coroutine-based one
3.1 Problem Definition
Our goal in this section will be to produce the set of multi-radix numbers in lexicographic (dictionary) order given a multi-radix base . More specifically, given a list of positive numbers, produce all lists of the same length as such that , in lexicographic order. Here is an example:
>>> M = [3, 2, 4]
>>> for a in multiradix_recursive(M):
... print(a)
...
[0, 0, 0]
[0, 0, 1]
[0, 0, 2]
[0, 0, 3]
[0, 1, 0]
[0, 1, 1]
[0, 1, 2]
[0, 1, 3]
[1, 0, 0]
[1, 0, 1]
[1, 0, 2]
[1, 0, 3]
[1, 1, 0]
[1, 1, 1]
[1, 1, 2]
[1, 1, 3]
[2, 0, 0]
[2, 0, 1]
[2, 0, 2]
[2, 0, 3]
[2, 1, 0]
[2, 1, 1]
[2, 1, 2]
[2, 1, 3]
In other words, the combinatorial set of objects being generated is the Cartesian product
where . So those of you familiar with Python's itertools module might already have thought of a quick solution to the problem:
from itertools import product
def multiradix_product(M):
return product(*(range(x) for x in M))
This, of course, is not an algorithm as much as it is delegating the task! Nonetheless, it is a good start and we will use it as a base-line for performance comparisons of the rest of the algorithms. We will also briefly look at how Python's itertools.product function is implemented internally after we discuss our algorithms.
3.2 An Algorithm Based on Arithmetic
To start with our first solution, let's observe that with , the problem is reduced to counting in binary:
>>> M = [2, 2, 2]
>>> for a in multiradix_recursive(M):
... print(a)
...
[0, 0, 0]
[0, 0, 1]
[0, 1, 0]
[0, 1, 1]
[1, 0, 0]
[1, 0, 1]
[1, 1, 0]
[1, 1, 1]
This observation leads to the following iterative solution: simply start from zero and count to , and covert the numbers to the multi-radix base given by , similar to how we convert numbers to binary. This results in the following code.
from operator import mul
from functools import reduce
def number_to_multiradix(M, x, a):
n = len(M)
for i in range(1, n + 1):
x, a[-i] = divmod(x, M[-i])
return a
def multiradix_counting(M):
n = len(M)
a = [0] * n
last = reduce(mul, M, 1)
for x in range(last):
yield number_to_multiradix(M, x, a)
We can classify this algorithm as an iterative algorithm that relies on the arithmetical properties of the objects we are generating. Because of this, it it does not have a very combinatorial feel to it. It also happens to be quite slow, especially in Python, since every number in is recalculated each time, and multiple divisions have to happen per generated object.
3.3 A Recursive Algorithm Based on Reduction to Subproblems
Next approach is the recursive one. To use recursion, we need to reduce the problem to a subproblem. Say has items in it, so we are producing multi-radix numbers with digits. Let . That is, is the first elements of . Then if we have a list of multi-radix numbers for in lexicographic order, we can extend that list to a list of lexicographic numbers for by appending to to each element of the list. This approach leads to the following recursive code:
def multiradix(M, n, a, i):
if i < 0:
yield a
else:
for __ in multiradix(M, n, a, i - 1):
# Extend each multi-radix number of length i with all possible
# 0 <= x < M[i] to get a multi-radix number of length i + 1.
for x in range(M[i]):
a[i] = x
yield a
def multiradix_recursive(M):
n = len(M)
a = [0] * n
return multiradix(M, n, a, n - 1)
Quite simple and elegant, and as we will see, quite fast as well.
3.4 An Iterative Algorithm
Now, let's look at the iterative approach. Since our goal is to go from one given multi-radix number to the next in lexicographic order, we can start scanning from right to left until we find an index in that we can increment, do the incrementation, and then set everything to the right of that index to . For example, if our multi-radix number system is simply given by , so we simply have decimal numbers of digits, and our current is then scanning from right to left tells us that is the first number that can be incremented, so we increment getting and then set everything to the right of to getting which is the next number in lexicographic order. We can also just set numbers that can not be incremented to zero as we do the scanning for the first number to increment, which will save us from having two loops. This approach results in the following code:
def multiradix_iterative(M):
n = len(M)
a = [0] * n
while True:
yield a
# Find right-most index k such that a[k] < M[k] - 1 by scanning from
# right to left, and setting everything to zero on the way.
k = n - 1
while a[k] == M[k] - 1:
a[k] = 0
k -= 1
if k < 0:
# Last lexicographic item
return
a[k] += 1
3.5 A Coroutine-Based Algorithm
Finally, let's look at the coroutine-based algorithm. The basic idea here is very similar to the previous iterative algorithm, but the execution is very different.
To explain this algorithm, I will borrow Knuth's style of explaining his coroutine-based algorithms in [KR]. Picture a line of friendly trolls. Each troll, with the exception of the first troll holds, a number in his hand. The trolls will behave in the following manner. When a troll is poked, if the number in his hand is strictly less than (meaning the number can be increased) he simply increments the number and yells out "done". If the number in his hand is equal to then he changes the number to and then pokes the previous troll without yelling anything. The first troll in line is special; whenever poked, he simply yells out "last" without doing anything else.

Picture a line of friendly trolls, such as the above, but each holding a number in his hand.
We will call the last troll in line (corresponding to index ) the lead troll. The algorithm will start with all trolls holding the number in their hands. Each time we need the next item generated, we poke the lead troll. If we hear "done" then we know we have a new item. If we hear "last" then we know that we are at the end of the generation task.
In the implementation of the above idea, each troll becomes a coroutine. Yelling out "done" will be yielding True and yelling out "last" will yielding False. Troll number is a special nobody coroutine that simply yields False repeatedly:
def nobody():
while True:
yield False
The rest of the trolls are instances of the troll coroutine in the code given below. Each troll creates the troll previous to it in line, until we get to troll number , which creates a nobody coroutine as its previous troll.
from nobody import nobody
def troll(M, a, i):
previous = troll(M, a, i - 1) if i > 0 else nobody()
while True:
if a[i] == M[i] - 1:
a[i] = 0
yield next(previous) # Poke the previous troll
else:
a[i] += 1
yield True
def multiradix_coroutine(M):
n = len(M)
a = [0] * n
lead = troll(M, a, n - 1)
yield a
while next(lead):
yield a
3.6 Discussion
In the previous sections we saw four algorithms that solve the problem of generating multi-radix numbers in lexicographic order. The four algorithms were
- multiradix_counting: an iterative algorithm based on arithmetic,
- multiradix_recursive: a recursive algorithm that reduced the problem to a subproblem,
- multiradix_iterative: an iterative algorithm that explicitly produced the next item in lexicographic order,
- multiradix_coroutine: a coroutine-based algorithm.
We also saw how to solve the problem using Python's built-in itertools.product function. The latest was implemented as multiradix_product. Let's look at a simple performance comparison of the five by having them generate all multi-radix numbers with , in other words, the digits of all 7-digit numbers in base ten. The result is shown below.
Testing multiradix_product:
Function test_generator took 0.472 seconds to run.
Testing multiradix_counting:
Function test_generator took 26.281 seconds to run.
Testing multiradix_recursive:
Function test_generator took 1.721 seconds to run.
Testing multiradix_iterative:
Function test_generator took 3.687 seconds to run.
Testing multiradix_coroutine:
Function test_generator took 4.726 seconds to run.
So to rank them in order of efficiency, based on this simple test: we have
- multiradix_recursive
- multiradix_iterative
- multiradix_coroutine
- multiradix_counting
The method based on arithmetic is the slowest by a large margin. This makes sense, provided that we are dealing with base ten numbers, not a power of two which computers are much better at dealing with. On top of that, Python is notoriously slow at numeric calculations.
And the fastest, of course, is using the built-in itertools.product method, which is not surprising in the least because it is implemented in C. However, it is interesting to find out which, if any, of the above algorithms is used to implement Python's itertools.product function. For this, let's have a look at Python's source code, file itertoolsmodule.c (see [PY-2]). The relevant section is inside the product_next function:
/* Update the pool indices right-to-left. Only advance to the
next pool when the previous one rolls-over */
for (i=npools-1 ; i >= 0 ; i--) {
pool = PyTuple_GET_ITEM(pools, i);
indices[i]++;
if (indices[i] == PyTuple_GET_SIZE(pool)) {
/* Roll-over and advance to next pool */
indices[i] = 0;
elem = PyTuple_GET_ITEM(pool, 0);
Py_INCREF(elem);
oldelem = PyTuple_GET_ITEM(result, i);
PyTuple_SET_ITEM(result, i, elem);
Py_DECREF(oldelem);
} else {
/* No rollover. Just increment and stop here. */
elem = PyTuple_GET_ITEM(pool, indices[i]);
Py_INCREF(elem);
oldelem = PyTuple_GET_ITEM(result, i);
PyTuple_SET_ITEM(result, i, elem);
Py_DECREF(oldelem);
break;
}
}
Of course, this is precisely our multiradix_iterative, with reference counting added.
Our coroutine-based algorithm lags behind all the other ones in terms of performance except for the arithmetic one. This is not surprising given the overhead of calling coroutines in Python. However, the coroutine-based approach will allow us to solve certain problems in very interesting ways, as we will see.
One last thing to note before moving on is that the coroutines given above can continue to be called even after False is yielded. In this case, doing so will result in the list being generated again from scratch, since all the numbers will have been set to zero by the time we get to nobody and other than that all the coroutines are ready to run again. As we will see, this is an interesting property of the coroutine based algorithms, and all of them will behave in this manner. That being said, in most of them, unlike this particular example, the order in which the list is generated is reversed each time False is yielded.
4 Binary Reflected Gray Codes
Now, let's consider the case of binary reflected Gray codes and see if we can apply our coroutine-based approach to this problem.
4.1 Problem Definition
For a full introduction and discussion of binary Gray codes, refer to either [KNUTH-4A] or [RUSKEY]. A binary Gray code is a listing of all binary strings of length such that each two subsequent strings are different in exactly one index. The binary reflected Gray code (BGRC), is one such code. It is given by recursively generating the BGRC for , then prepending a zero to all strings, and a one to all the strings in reverse order. A very naive recursive implementation in Python, which requires the whole code to be kept in memory, is given below, as a more precise definition.
def gray(n):
if n > 0:
g = gray(n - 1)
gr = reversed(g)
return (['0' + a for a in g] +
['1' + a for a in gr])
else:
return ['']
And example output:
>>> for a in gray(3):
... print(a)
...
000
001
011
010
110
111
101
100
4.2 A Coroutine-Based Algorithm
The first example in [KR] is precisely BGRC, although it is presented as the ideals of the totally disconnected poset with vertices. To continue with the trolls of last section, again we have a line of trolls, with first troll in line being the special troll that simply yells out "last" when poked. This time, however, each troll is simply holding a light in his hand, which is either on or off. The trolls are also now either asleep or awake. If a sleeping troll is poked, he simply wakes up and pokes the previous troll. When an awake troll is poked, he just switches the light (from on to off, or off to on) and yells "done".
It is relatively easy to see that the index of the first awake troll, starting from the right, follows the ruler sequence ( ). Once this is established, the fact that the algorithm produces the BGRC can be shown immediately. I encourage you to convince yourself, mentally or using a pen and paper, that the above does indeed work as explained.
As for the implementation using coroutines, the awake or asleep state of each troll is simply a matter of which instruction the coroutine will resume from when called next. We will not need a variable to keep track of it. This results in the code for this algorithm to be deceiving simple. The "lead" coroutine will again be the last one, and we start the list with the all zeros list. Putting it all together we have the following code.
from nobody import nobody
def troll(a, i):
previous = troll(a, i - 1) if i > 0 else nobody()
while True:
a[i] = 1 - a[i]
yield True
yield next(previous)
def setup(n):
a = [0] * n
lead_coroutine = troll(a, n - 1)
return a, lead_coroutine
def gray(n):
a, lead = setup(n)
yield a
while next(lead):
yield a
With this algorithm, when False is yielded the first time, a will be set to the all ones string. As such, if we run the algorithm a second time, we get the BGRC in reverse order. This can be repeated ad infinitum.
5 Steinhaus-Johnson-Trotter Permutation Generation
5.1 Problem Definition
SJT is an algorithm for generating all permutations in Gray order. Here, Gray order means that "distance" between two subsequent permutations is one, where a distance of one means that they differ from each other by one swap of adjacent elements, also called a transposition. The basic idea of the algorithm is recursive. Given a list of permutations of , we can produce a list of permutations of by inserting into each permutation of , first by starting at the very right end and moving to the left, and then moving to the right, and so on. Here is an example output for .
123
132
312
321
231
213
Here, given the permutations and for , SJT inserts at the end of and then moves it to the left until it can not move any further, then moves on to the next permutation of which is and inserts at the left end, and then moves it to the right until it can no longer move.
A simple recursive implementation of this algorithm is given below.
def permutations(n):
if n:
r = list(range(n))
for pi in permutations(n - 1):
for i in r:
yield pi[i:] + [n] + pi[:i]
r.reverse()
else:
yield []
5.2 A Coroutine-Based Algorithm
Now let's implement SJT using our coroutine-based approach. Picture our troll friends again, standing in a line, and as they did before, each troll is assigned a number that they will remember, between and . This time, however, they no longer hold a number in their hands. Instead, the numbers are laid out in a row on a table, starting in increasing order: . Each troll also keeps track of his "direction", which is either left or right. All trolls start with direction left at the beginning. Number is not on the table since troll number is again the special troll that just yells "last" when poked.
When poked, trolls will walk up to the table and find their number in the row. They will then look at the number next to their number based on their current direction (which they meticulously remember!). If the next number is larger than theirs, or there is no next number, meaning their number is the last or first in the row (depending on direction), then then they just poke the previous troll in line, and switch their direction to be opposite of what it used to be. Otherwise, they move their number, changing its place with the number next to it that it was compared to. In this case, they simply yell out "done".
As before, I encourage you to convince yourself that the above does in fact produce all permutations in SJT order.
For the coroutine implementation, we follow the above algorithm quite closely, but add a few things for simplicity. First, we pad both sides of our permutation with the number , which is greater than all numbers in the permutation. These two numbers will never move and their purpose is to simplify the code, since we now never have to worry about invalid indices, since we will always hit a "fence before falling off the cliff". This way we can just check to see if our number is greater than the next number before doing a swap.
The end result is the following code.
from time import sleep
def nobody():
while True:
yield False
def setup(n):
# Start with the identity permutation with 0 padded on both sides
# Example: for n = 4, pi starts as [0, 1, 2, 3, 4, 0]
# The zeros act as "fixed barriers", never moving
pi = list(range(n + 1)) + [0]
# The inverse permutation starts as the identity as well. It does not need
# the fixed barriers since their inverses will never be looked up.
inv = pi[:-1]
def troll(i):
"""
The goal of troll[i] is to move i in the direction of until it hits a
"barrier", defined as an element smaller than it.
"""
neighbour = troll(i + 1) if i < n else nobody()
d = 1
while True:
# j is the element next to i in pi, in direction d
j = pi[inv[i] + d]
if i < j:
# Swap i and j
pi[inv[i]], pi[inv[j]] = j, i
inv[i], inv[j] = inv[j], inv[i]
yield True
else:
# Change direction and poke
d = -d
yield next(neighbour)
# The lead coroutine will be the coroutine in charge of moving 1
return pi, troll(1)
def permutations(n):
pi, lead = setup(n)
yield pi[1:-1]
while next(lead):
yield pi[1:-1]
def main():
s = set()
n = 4
pi, lead = setup(n)
while True:
s.add(tuple(pi[1:-1]))
print(pi[1:-1])
if not next(lead):
print('----', len(s), '----')
sleep(1)
s.clear()
if __name__ == '__main__':
main()
5.3 Discussion
First, let's have a look at the performance of the two implementations by having them generate all (about million) permutations of , and compare the running times:
Testing coroutine-based algorithm:
Function test_generator took 3.944 seconds to run.
Testing recursive algorithm:
Function test_generator took 4.374 seconds to run.
This time the coroutine-based implementation is slightly faster than the recursive one.
One last thing to note about this particular example is that similar to our BGRC example, if run through again, the coroutines will generate the permutations in reverse order. For example, with we get:
123
132
312
321
231
213
-------
213
231
321
312
132
123
-------
123
132
312
321
231
213
-------
...
6 Ideals of a Poset Consisting of Several Chains
6.1 Problem Definition
Now let's consider another example taken from [KR]. In this example, the goal is to generate all ideals of a poset consisting of several chains, in Gray order. In simpler terms, we are to generate all binary strings of length such that given some set with
we have
This is the same thing as requiring that
We can see right away that BGRC is a speical case of this one, with , which reduces the above to a vacuous condition that is satisfied by any binary string.
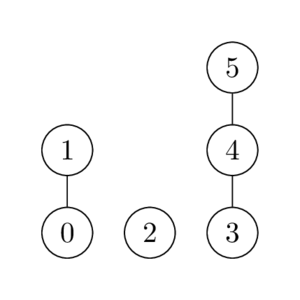
The poset poset corresponding to . If is above then we must have .
Here is an example of the desired code for and . There are strings in the code total.
000000
000001
000011
000111
001111
001011
001001
001000
011000
011001
011011
011111
010111
010011
010001
010000
110000
110001
110011
110111
111111
111011
111001
111000
6.2 A Coroutine-Based Algorithm
In this example again, we will have our friendly trolls, with lights in their hands. They are however, no longer in a neat and tidy straight line. Instead, Each troll is next to potentially two other trolls, whom he can poke if needed. Let's call numbers that are at the bottom of a chain "lead" numbers. These are precisely the numbers in . Trolls with lead numbers will have a access to the previous lead coroutine, and all trolls will have a reference to the troll with the number above them. If there is no number above or to the left of a number, then the corresponding trolls will be the special nobody trolls that always yell out "last".
For example, in the above diagram troll[0].above = troll[1] and troll[2].prev_lead = troll[0]. On the other hand, troll[5].above = troll[5].prev_lead = nobody().
Similar to the BGRC case, our trolls will be sleeping or awake. The rules for whom to poke and when to turn the light on and off is a bit more complicated however. This time, the troll's behaviour depends not only on whether he is asleep or awake, but also on whether his light is on or off. Instead of explaining it here, I will let the code do the explanation with some added comments.
from nobody import nobody
def troll(E, n, i, a):
above = nobody()
prev_lead = nobody()
if i + 1 not in (E + [n + 1]):
above = troll(E, n, i + 1, a)
if i in E and i != 0:
prev_lead = troll(E, n, E[E.index(i) - 1], a)
while True:
# Awake and light off - a[i] = 0
while next(above):
yield True
a[i] = 1
yield True
# Asleep and light on - a[i] = 1
yield next(prev_lead)
# Awake and light on - a[i] = 1
a[i] = 0
yield True
# Asleep and light off - a[i] = 0
while next(above):
yield True
yield next(prev_lead)
def setup(E, n):
a = [0] * n
lead_troll = troll(E, n - 1, E[-1], a)
return a, lead_troll
The basic idea is to set bits to one starting from the top of the last chain, and once all the bits in the last chain are set to one, call the coroutine for the previous lead to go to the next string given by the previous chains, and then start setting bits to zero starting from the bottom of the chain. Because of this, the algorithm is a bit similar to our SJT algorithm as well.
This is our most complicated example so far so I highly recommend you spend the time needed to make sure you understand it fully.
7 Conclusion
We looked at a variety of combinatorial generation algorithms implemented using coroutines. With the examples provided, I hope to have at least created some intrigue regarding the use of coroutines in solving combinatorial generation problems. It is my belief that with each style of attacking a combinatorial generation problem, comes a "mode" of thinking. With recursive algorithms, the mode of thinking involves finding ways to reduce the problem to a subproblem; that is, if we have the solution to a smaller instance of the problem, how can we extend it to a solution for the larger instance? With the iterative approach, the mode of thinking either involves imitating what a recursive algorithm does in an iterative way, or it involves finding ways of going explicitly from one object to the next in the desired order. With both of these, the mode of thinking is somewhat "global". What I mean by this is that we are standing outside, looking at the whole list or object, and writing code that deals with the whole list or one object at a time.
With coroutines, the mode of thinking becomes more "local". We are no longer looking at the whole list or even a single object, but a single bit or number in a single object. This mode of thinking involves finding rules by which the coroutines representing the bits or numbers in the objects we are generating need to behave and interact with each other so as to produce the desired end result. I believe that this mode of thinking, apart from being interesting and novel of and by itself, can be applied to a variety of problems. It is also quite possible that the mode of thinking might be transferable to other areas, for example parallel processing and multi-tasking, which are the areas coroutines have typically been used in.
For those of you interested in learning more [KR] continues generalizing the BGRC and chain poset algorithms that we saw here, with the final algorithm generating the ideals of any given poset. The source code repository for this article has a few more examples in Python, including one for generating ideals of the zig-zag poset in zigzag.py.
8 References
| [BEAZLEY] | A Curious Course on Coroutines and Concurrency, David Beazley |
| [KNUTH-1] | The Art of Computer Programming - Volume 1: Fundamental Algorithms, Third Edition, Donald Knuth |
| [KNUTH-4A] | The Art of Computer Programming - Volume 4A: Combinatorial Algorithms, Part 1, Donald Knuth |
| [KR] | Deconstructing Coroutines, Donald Knuth and Frank Ruskey |
| [PEP-255] | Python Enhancement Proposal 255 - Simple Generators |
| [PEP-342] | Python Enhancement Proposal 342 - Coroutines via Enhanced Generators |
| [PEP-380] | Python Enhancement Proposal 380 - Syntax for Delegating to a Subgenerator |
| [PY-1] | The Python Language Reference - The yield Keyword |
| [PY-2] | Python 2.7.1 Source Code - itertoolsmodule.c File |
| [RUSKEY] | Combinatorial Generation, Frank Ruskey |
Comments